To Sum or Not to Sum
Why Summarize?
Internet is a treasure trove of information. But imagine having to dive into the proverbial haystack to find your needle of useful information. Just in this case it’s a vast ocean of haystacks. Just for a simple “What is Data Science?” we get this
Wouldn’t it be convenient to have the crux of this information at hand? To have all the redundancy in data be removed to have our time spent on learning additional information.

This is where Automatic Summarization systems come to our rescue. It does exactly as advertised, go through huge quantities of data and create a concise and comprehensible summary of the same, ensuring information consistency at the same time.
How does it work?
We can go about summarizing things in 2 ways:
- Taking key pieces of information from the sources and reorder them to present a short chunk of text that covers all the topics. This is known as Extractive Summarization.
- The other & more “human” is to go through the data first & then writing a summary from scratch, rephrasing/paraphrasing as per requirement. This is the Abstractive Summarization method. Ideally these would seem better but they are more difficult to build & operate.

What is a good summary?
It’s one thing to get a summary but how can we decide upon it’s quality? While manually evaluating it might be the best way, it’s not scalable. So we work by comparing our summaries with the gold (ideal) summaries. This is done through calculating the Precision/Recall scores of the n-gram overall the two summaries. Some of the common approaches are BLEU & ROUGE.
Where do we come in this?
Now that you have a good idea of what summarizers are, you can check out Connexun’s summarizers to generate automatic summaries.
But even for summarization, the information overloading makes it tough on text mining. Our summarizer mitigates this by finding the most representative sentences of news content. This is done via analyzing the relative (to the mean) sentence length along with the position of the sentence.
You can also indicate the total number of sentences. Pretty cool right
You can play around with the **Live Demo** by simply inserting a URL as shown:

Language Models
Well it’s one thing to take out parts of text to build summary. But for abstractive summarization there’re 2 tasks:
- Capturing the entire context of the data without leaving any information
- Creating a grammatically correct new summary out of the captured information
Now maybe you’ll be able to extract the important sentences & keywords from the text, but creating a comprehensible summary out of it is another task. Since even we as humans are not able to write correct English compositions before a few years of formal training. So for training such models we require large amount of annotated data. Even after that these models are not generalizable to other tasks.
Here in language models come to our rescue. Specifically OpenAI GPT & GPT-2 (Generative Pre-Training) are a major leap in NLP. The key idea was to train a generative model on unlabeled data (just loads of text essentially). Followed by this, we can train the models providing specific data tasks like classification, sentiment analysis, summarization etc.
GPTs
The key idea of GPT is learning a generative language model using unlabeled data & then fine-tuning the model by providing data for desired tasks like, classification, sentiment analysis, & summarization.
Consider it like this
- You’re 1st training a simple model on lots of text that essentially train it in the English language. It generates text with context to the input.
- Followed by this, we provide labeled data in context to the task at our hand.
GPT-2 consists of a few additional novelties over it’s predecessor:
- Instead of P(Output | Input), it had a newer objective of P(Output | Input, Task). This is called task conditioning, where the task is expected to different output for the same input based on the kind of task. But instead of feeding the task at an architectural level, it was fed a natural language sequence.
- Due to this task conditioning, the model was capable of zero-shot learning, where the nature of the task is understood by the model purely based on task instructions.
Architecture & Implementation
The authors created a greater dataset called WebText by scraping Reddit (the source of all internet memes & a lot more) outbound links of highly upvoted articles. After cleaning, the document consisted of 8 million documents. The model has 48 layers & uses 1600 dimensional word vectors for word embedding. The vocabulary has 50,257 tokens. Batch Size of 512 & a context window of 1024 tokens were used.
Layer normalization was done before input of each sub-block & an additional layer normalization was added after the final self-attention block.

Performance
GPT-2 improved upon the then existing state-pf-the-art for 7/8 language modelling datasets in a zero-shot setting. Similarly it outperformed 3/4 baseline models in reading comprehension tasks in zero shot setting.
But it too had it’s limitations, it still couldn’t outperform the state-of-the-art unsupervised model in French to English translation task.
An interesting observation that the authors observed that contrary to the general trends of saturation, the model performance increased in a log-linear fashion with increase in the capacity of the model.
So going on with bulldozing the model size, OpenAI developed the GPT-3 model with 175 billion parameters (100 times more than GPT-2). This it perform well on many downstream NLP tasks in zero/few-shot setting.
It’s larger capacity allowed for writing of articles indistinguishable from humans. It can also perform on-the-fly tasks on which it was never explicitly trained on, like summing up numbers, unscrambling words in a sentence & writing codes given natural language description of task.

Use-Cases
Well now that you get the feel of text summarizers, where exactly are they present in the real world.
Information Extraction via News Media
Quite a lot of our information comes from Newspapers. But given their vast numbers, specially with the advent of online news forums, it has become extremely difficult to get an actual and accurate description of events. Summarization can help with understanding the kind of media coverage a event has associated with it.

Along with this, quite a lot of business decisions are based upon the current laws & relation between nations. For example, if a company is planning to setup a manufacturing unit in another country, you would need to know about the socio-economic condition of the nation and the current relations with your government. These factors, though seemingly small, play a pivotal role in many business decisions.
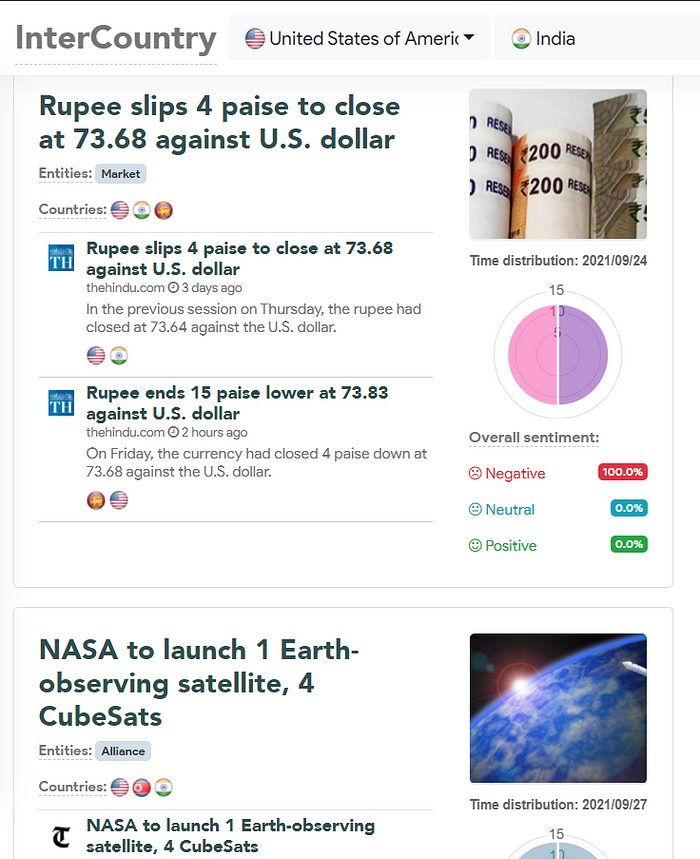
Summarization along with sentiment analysis can help you see the top news in domains & better understand their net effect as positive or negative.
Social Media Posts/Tweets
With close to 3 million FB & 474,000 Tweets per minute, platforms like Facebook & Twitter have become the fastest medium of information travel these days. But taking out accurate information and deciding on the key facts regarding an event manually becomes impossible at this scale.
This is where summarization comes to our rescue. Using it in conjunction with Sentiment Analysis can help us understand the emotion of the masses & act accordingly. Social Engineering has boomed as a field today that help politicians and celebrities cater better to the masses.

Financial & Legal Documents
It’s quite often that we get intimidated by the large financial documents like Annual Reports, statements & prospectuses. Legal documents are another such avenues where we need specific information buried under technical jargon.
Automatic Summarization systems excel at extracting this information. Additional input query options can help you get the desired information in context to your queries.

Conclusion
In this article, you came to know about what summarizers are, their types & inner working. We came to know about the latest buzz in NLP, the GPT language models with special focus on the widely used GPT-2 and what makes them tick. A brief description into the latest GPT-3 was also covered.
Finally we came upon the use-cases for summarizers & how we at Connexun are bringing these models to real world applications through our News API & Text Analysis API. In there you can find demo for our other products like Geoparser & Sentiment Evaluator.
So now we know the what, why & how of summarizers, armed with this knowledge you are ready to dive into the haystack of the internet to find your needle.
About Connexun
Connexun is an innovative tech startup based in Milano, Italy.
Connexun crawls news content from tens of thousands of open web sources worldwide; turning unstructured web content into machine-readable news data APIs. Its AI powered news engine B.I.R.B.AL. empowers organizations to transform the world’s news into real-time business insight.
To learn more about Connexun, subscribe to our medium blog, follow us on Linkedin, Twitter, Facebook, and visit our demos.
